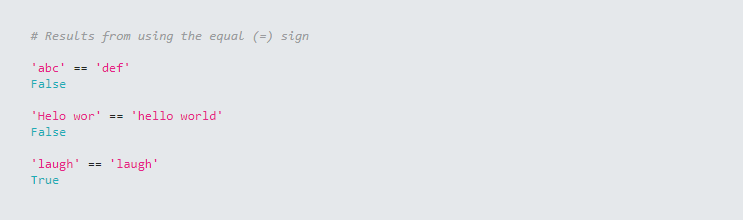
Have you ever wanted to determine just how similar two strings are? Using the equal sign returns whether two strings are the same or not. It does not give any information or measure regarding how similar or dissimilar two strings are.
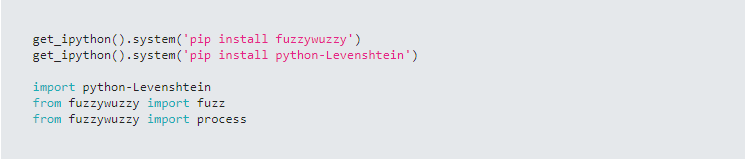
Python’s Fuzzywuzzy library contains many methods that can be used to compute a similarity measure for two strings. The Fuzzywuzzy library contains a module called fuzz that contains several methods that can be used to compare two strings and return a value from 0 to 100 as a measure of similarity.
Strings that are completely different would have a similarity score of 0 whereas strings that a completely identical would have a similarity score of 100. Strings with some level of similarity would fall between 0 and 100.
Fuzzywuzzy uses Levenshtein Distance to calculate the differences between sequences. This library also utilises the difflib library under the hood of all of its calculations.
The string comparison methods within the fuzz module of the Fuzzywuzzy library are:
The following code demonstrates how some of these methods work on strings of varying similarity.
Fuzzywuzzy uses Levenshtein Distance to calculate the differences between sequences. This library also utilises the difflib library under the hood of all of its calculations.
The string comparison methods within the fuzz module of the Fuzzywuzzy library are:
- QRatio
- UQRatio
- UWRatio
- WRatio
- partial_ratio
- partial_token_set_ratio
- partial_token_sort_ratio
- ratio
- token_set_ratio
- token_sort_ratio
The following code demonstrates how some of these methods work on strings of varying similarity.

Fuzzywuzzy also contains a module called process which contains methods for determining how similar one string is to a list of other strings.
The methods in the process module are as follows:
The following code demonstrates how some of these methods work.
The methods in the process module are as follows:
- extract
- extractBests
- extractOne
- extractWithoutOrder
- dedupe
The following code demonstrates how some of these methods work.

The Fuzzywuzzy library has many use cases. Imagine trying to determine how similar names, addresses, telephone numbers and dates are between two datasets. This library can be used to find matching records between datasets where a similarity score makes more sense over a definitive True or False regarding equality.
Happy Learning!
Happy Learning!

 RSS Feed
RSS Feed
