Data Scientists sometimes alternate between using Pyspark and Pandas dataframes depending on the use case and the size of data being analysed. It can sometimes get confusing and hard to remember the syntax for processing each type of dataframe. The following cheat sheet provides a side by side comparison of Pandas and Pyspark syntax needed to accomplish some common programming tasks.
|
WHAT IS GRAPH THEORY AND NETWORK ANALYSIS Graph Theory is the mathematical study of the properties and applications of graphs. Graphs are mathematical structures used to model pairwise relations between objects. Graphs are also referred to as networks and contain a set of vertices/nodes/points connected by edges/links/lines. 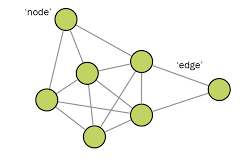 Graph Theory can be applied to Network Analysis, Link Analysis and Social Network Analysis. These types of analysis borrow notations from Graph Theory and are focused on investigating social structures represented as networks, by applying a variety of mathematical, computational and statistical techniques. HISTORY OF GRAPH THEORY Graph Theory was first introduced and studied in 1736 by Leonhard Euler who was interested in solving the Konigsberg Bridge Problem. Konigsberg was a city in Prussia, Russia with the river Pregel flowing through it creating two islands. The city and islands were connected by seven bridges. The goal of the Konigsberg Bridge Problem was to devise a walk through the city that would cross each of the 7 bridges once and only once with no doubling back, ensuring that you ended where you started. 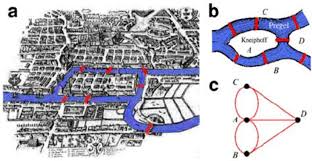 ABOUT IBM NLU
IBM Natural Language Understanding (NLU) can be used to analyze the semantic features of text such as the content of web pages, raw HTML and text documents. NLU also has the ability to analyze target phrases in context of the surrounding text for focused sentiment and emotion results. The semantic features that can be extracted from URLs, raw HTML and text using NLU include:
Have you ever wanted to determine just how similar two strings are? Using the equal sign returns whether two strings are the same or not. It does not give any information or measure regarding how similar or dissimilar two strings are. 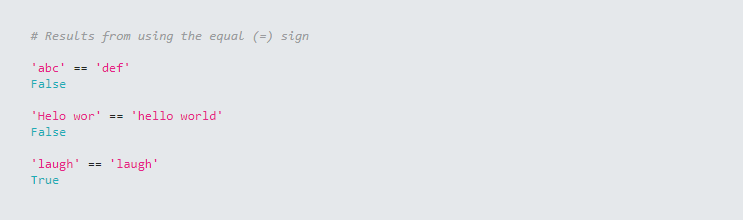 Python’s Fuzzywuzzy library contains many methods that can be used to compute a similarity measure for two strings. The Fuzzywuzzy library contains a module called fuzz that contains several methods that can be used to compare two strings and return a value from 0 to 100 as a measure of similarity. 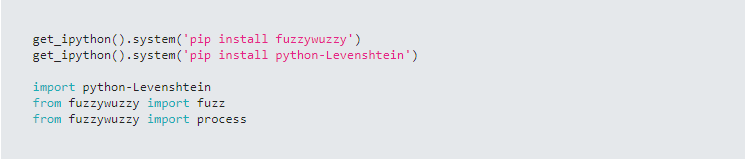 |
AuthorMy name is Vanessa Afolabi also known as @TheSASMom. I am a Data Scientist fluent in SAS, R, Python and SQL with a passion for Machine Learning and Research. Archives
August 2019
Categories |
 RSS Feed
RSS Feed
